

Arquitectura y hospedaje de Blog Stack
Escrito por
picodotdev el , actualizado el .
software
software-libre
java
programacion
planeta-codigo
Enlace permanente
Comentarios

Normalmente en esta bitácora suelo poner ejemplos para explicar como funciona una determinada herramienta, son ejemplos que podrían aprovecharse para algo productivo pero para mantenerlos simples por si mismos no suelen serlo. En esta entrada voy a comentar cual es la arquitectura y como está alojado Blog Stack, que es un ejemplo de algo práctico y real por si la experiencia de este ejemplo le sirve de ayuda o de inspiración a alguien. En la red he encontrado comentada la experiencia de Planeta Linux y Meneame, otros proyectos web.
Blog Stack (BS) es una agregador, planeta, o fuente de información de bitácoras sobre programación, desarrollo, desarrollo ágil, software, software libre, hardware, gnu/linux o en general temas relacionados con la tecnología, en definitiva es un servicio que está disponible en una dirección de internet, www.blogstack.info.
Una condición importante que buscaba para BS es que de cualquier opción no debería ser muy cara al menos en los inicios hasta que viese cuales eran los ingresos por la publicidad que era capaz de generar, estimaba que no iban a ser muchos hasta que se agregase unas decenas de bitácoras y tuviese algunos lectores suscritos a las fuentes se sindicación. Por coste cualquier opción que fuese en la nube prácticamente quedaba desechada, la opción más barata era la de Amazon EC2, reservando una instancia t1.micro (0,615 GB) por tres años el coste era de unos 80 € anuales y de 140 € anuales para una instancia de tipo m1.small (1,7 GB), otras opciones como OpenShift con la capa gratuita de 3 gears si un small gear (512 MB) era suficiente no tenía coste pero si necesitase un gear medium (1 GB) el coste era superior, de unos 438 € anuales. Finalmente otra opción que evalué era Google Compute con un coste de 115 € anuales para una instancia f1-micro (0,60 GB) y de 305 € para una g1-small (1,7 GB). Si en cualquier opción de estas en la nube el coste debía de asumirlo yo probablemente al cabo de un tiempo, pocos años, acabaría cerrando el servicio, por ello el coste era importante. OpenShift y su capa gratuita tenía muchas posibilidades.
Por otro lado estaba bastante contento con la generación estática de mi bitácora con Octopress y el alojamiento en GitHub Pages. Me pereció que una opción con un coste mínimo podría generar de forma estática el contenido y alojarlo en GitHub Pages al igual que hago con Octopress. Finalmente, me quedaba donde hacer la generación estática, otra opción era usar la Raspberry Pi pero esto me obligaba a mantenerla encendida siempre, cualquier problema en la Raspberry Pi o conexión en mi red o si la necesitaba apagar en algún momento podría dejar BS sin actualizarse. Si era posible necesitaba una forma de nube, por suerte OpenShift ofrece un plan gratuito de 3 gears con 512 MiB de memoria y 1 GiB de espacio en disco cada uno y en las primeras pruebas que hice era suficiente. Además, OpenShift ofrecía todas las herramientas que necesitaba git para subir el contenido estático al repositorio de GitHub, iconv, cron, bases de datos relacionales y no sql, poder usar Undertow como servidor y un «cartridge» diy («Do It Yourself»). Tenía varias piezas, finalmente elegí la combinación de OpenShift para la generación estática y GitHub Pages para servir el contenido. El contenido podría servirlo desde OpenShift pero no estaba seguro de que el gear fuese capaz de aguantarlo todo si el tráfico fuese grande. Por el espacio en disco de 1 GB tenía dudas de cuanto podría necesitar pero si fuera mucho podría adquirir 1 GiB adicionar por 1 € al mes.
Generar el contenido de forma estática tiene limitaciones y obliga a hacer las cosas de diferente forma que empleando una aplicación web pero el requisito del coste era más importante que la funcionalidad y la forma de ofrecerla. El coste de BS es de unos ¡10 €… al año! y consiste básicamente en la compra del dominio. El dominió lo compre en DonDominio por recomendación según la cual era buena opción, en los 10 € está incluido el WHOIS privado que en otras opciones tienen un coste adicional. Teniendo el nombre elegido de Blog Stack para el proyecto tenía que saber que dominios de nivel superior (TLD) estaban disponibles, los “okupas” de los dominios tenían reservado el .com y el .net, como BS era un sitio de información no me importó mucho comprar el .info.
Con todo la arquitectura de despliegue y hospedaje de Blog Stack es la siguiente:
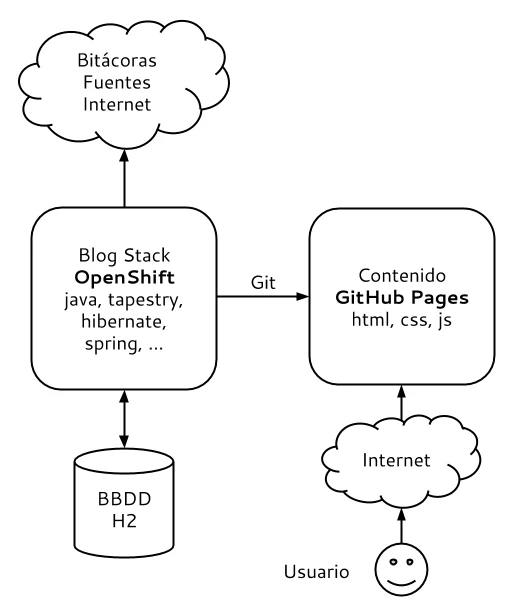
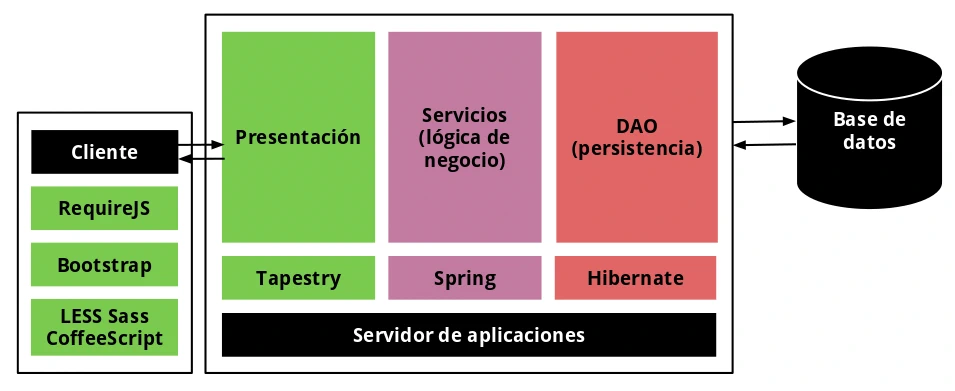
En cuanto a la aplicación y el código Java en si las partes importantes están en un servicio que se encarga de la indexación extrayendo el contenido de las fuentes y guardalo en una base de datos, otro servicio para la generación del contenido del sitio de forma estática (html, css, js, imgs, …) y finalmente el programa Java principal que sirve para lanzarlo desde la linea de comandos, el resto son las clases del modelo de datos y los DAO de persistencia y acceso a dataos. La aplicación sigue el esquema tradicional de 3 capas, la de presentación (páginas y componentes de tapestry), la de lógica de negocio formada por los servicios de indexación, generación y los DAOs (formada por el contenedor de servicios de tapestry y spring) y finalmente la capa de datos formada por una base de datos H2 (donde hibernate interviene). En realidad en BS no hay un servidor de aplicaciones sino que se usa Tapestry en una aplicación «standalone».
La raíz del proyecto fue que quería usar Apache Tapestry de alguna forma en algún proyecto que fuese de utilidad para otras personas, al mismo tiempo que meditaba la idea Planeta Linux dejó de funcionar durante unas semanas y tampoco estaba contento del todo con los otros planetas en los que tenía mi bitácora agregada. Con Planeta Arch Linux porque después de unos meses seguía sin ni siquiera respuesta a la solicitud de agregación y Planeta Código ya que creía que podría ofrecer mejor funcionalidad, por ejemplo, los gist no se importaban bien (utilizan javascript y por seguridad deben estar excluidos). Ya que empezaba el proyecto creía que podría proporcionar alguna idea que permitiese descubrir contenido a los usuarios a través de como hace stackoverflow con las etiquetas de modo que una persona se pueda suscribir (mediante rss/atom) a una etiqueta para recibir el contenido de solo el tema que le interese de cualquier bitácora agregada, descubrir nuevas bitácoras con contenido interesante a veces no es fácil. La opción más parecida y mejor que he encontrado es bitacoras.com, salvo las votaciones, el ranking y que tiene un ámbito más amplio al poder incluir bitácoras de más temáticas y que la agregación de bitácoras no está automatizada, BS en lo importante ofrece lo mismo de forma más simple y está más especializado tanto en la temática de las bitácoras como en la suscripción por etiquetas.
Apache Tapestry junto con el módulo Tapestry Offline y el hecho de que el contenedor de dependencias de Tapestry se puede usar en una aplicación «standalone» me permitía resolver la parte técnica en la mayor parte, el resto era usar unas cuantas librerías para tener la funcionalidad que necesitaba. Una de ellas era jsoup con la que podía filtrar el contenido agregado y evitar problemas de seguridad. Permitir en el contenido scripts e iframes puede ser un problema de seguridad pero permitiendo algunas fuentes confiables podía importar el contenido de forma segurar sin perder funcionalidades. En algunas bitácoras como la mía se suelen utilizar como trozos de código gist, vídeos de youtube o vimeo, presentaciones de Speaker Deck o usar el programa de afiliados de amazon. Iba a necesitar una base de datos ya que las entradas van desapareciendo de las fuentes agregadas a medida que se publica contenido. La base de datos que elegí fue H2 principalmente porque puede estar contenida en un archivo que puedo descargar a mi ordenador, de esta manera podría evitar los volcados de PosgreSQL. Si BS resultase que creciese bastante posteriormente podría cambiar H2 por PostgreSQL (la otra opción que consideraba), H2 al principio era más que suficiente. El resto era la colección de herramientas que se suelen utilizar el proyectos Java como Hibernate, Spring, Gradle, Apache Commons, Rome (para obtener las fuentes)…
El despliegue de nuevo código está totalmente automatizado tal y como aconseja el libro The Pragmatic programmer, con lo que me es muy simple y me consume muy poco tiempo hacer un nuevo despliegue, el tiempo ahorrado lo puedo emplear para desarrollar. El despliegue consiste en unos cuantos comandos ejecutados por una tarea de gradle que se envían a OpenShift. Los comandos de despliegue se encargan de todo mediante ssh, hacer previamente una copia de seguridad de la base de datos (scp/unzip), sincronizar los archivos cambiados del proyecto con rsync, establecer los permisos de ejecución de los archivos bash y actualizar el esquema de la base de datos con liquibase.
No estaba usando Apache Tapestry de la forma habitual que se suele emplear que es para desarrollar aplicaciones web que se despliegan en un servidor de aplicaciones Java. Lo iba a usar como motor de plantillas para generar el contenido estático, aparte de querer usar Tapestry ¿por que esta opción si hay soluciones específicas para esto como Thymeleaf, Freemarker, …? Uno de los motivos es que en en la mayoría de opciones se sigue un modelo «push» en el que se combinan los datos con la vista para producir el resultado. Este modelo «push» cada vez me convence menos a pesar de ser ampliamente usado en muchos motores de plantillas y frameworks web, la razón es que las vistas al final acaban conteniendo lógica si son algo complejas, eso no es bueno. Tapestry por el contrario usa un modelo «pull» en el que la plantilla para generar el contenido puede acceder al controlador por lo que las plantillas no tienen lógica, estando extraída a una clase java con lo que nos beneficiaremos del compilador y el IDE para esa lógica. Además, los componentes de Tapestry son una manera fácil de reutilizar código, por si fuera poco si pasado un tiempo quisiese desplegar Blog Stack como aplicación web podría aprovechar prácticamente todo el código.
Estando convencido del uso del software libre para ser coherente no tenía otra opción que publicar el código fuente bajo alguna licencia de software libre, la opción que elegí fue AGPL. Uno puede tener dudas de “dar” el código fuente pero creía que ganaba si alguien en un caso remoto hiciese un fork de BS, ya que Tapestry siendo una parte tan importante sería lo usado y por tanto habría hecho que otra persona usase Tapestry. Si basándose en la misma idea se hacía un proyecto similar competiríamos y que triunfase la mejor opción. Pero lo más probable que ocurra es que se colabore con el desarrollo de BS, con esta opción también ganaría. De tres opciones posibles en dos ganaría, en la tercera se competiría y las opciones que elegí eran de lo mejor que hay en el mundo Java, BS está bien armado.
Con el desarrollo de Blog Stack he tenido que resolver unos cuantos problemas, en posteriores entradas explicaré como he implementado las soluciones a algunas funcionalidades que son comunes a los proyectos web, como la correspondencia entre las urls y los artículos o etiquetas para no poner identificadores de entidades de la base de datos en las urls y que queden más limpias y amigables, como hacer la transliteración de los títulos de las entradas para la construcción de las urls, como obtener un extracto de la entrada (puede parecer simple pero no lo es tanto), como usar un servidor embebido que sirva el contenido estático o como procesar recursos estáticos como archivos less para generar el css con wro4j.



