

Iniciar un stack de servicios en un cluster de Docker Swarm
Escrito por
picodotdev el .
planeta-codigo
software-libre
Enlace permanente
Comentarios
Los stacks en Docker Swarm son definiciones en un archivo de texto en formato YAML de múltiples servicios además de volúmenes, redes de software y secretos. Esta definición de un stack ejecutado en un cluster de nodos Docker Swarm permite iniciar múltiples contenedores además de los otros elementos que necesiten para su funcionamiento. Los stacks son el equivalente para Docker Swarm de los archivos multicontenedor de Docker Compose, y el formato de ambos muy similar.

Con Docker Compose se pueden definir en un único archivo un conjunto de contenedores que forma un servicio o aplicación y que se lanzan como una unidad. En vez de ejecutar los comandos individuales que inician cada contenedor el archivo en formato yaml de Docker Compose define varios contenedores y al ser un archivo de texto es añadible a un sistema de control de versiones para registrar los cambios. La información del archivo de Docker Compose es la misma que se indicaría en el comando para iniciar un contenedor individual.
En versiones más recientes se ha modificado ligeramente el formato del archivo de Docker Compose para añadirle las características necesarias que necesita Docker Swarm, la herramienta integrada en Docker que permite crear clusters de nodos que ejecuten contenedores Docker. A estos archivos ahora se les denomina como stacks. Así hay nuevas secciones como services, networks, volumes y secrets entre otras para soportar algunas funcionalidades adicionales. La sección services es similar a la que usábamos en Docker Compose y define los contenedores. Por ejemplo, para definir que el servicio se componga de un contenedor con un servidor web nginx usaríamos el siguiente archivo. El parámetro version es muy importante ya que indica las opciones soportadas en el archivo.
|
|
A destacar las opciones deploy y replicas ya que indican cuantas instancias o contenedores de ese servicio habrá en el cluster. Al igual que con los comandos de Docker Swarm era posible crear redes por software a las cuales conectar los contenedores para que se puedan comunicar entre sí en la sección networks de cada servicio se indica las redes a las que conectarlo y en la sección a nivel raíz del archivo las redes a crear.
También hay una sección propia para definir los volúmenes que dependiendo del driver se integra con diferentes plataformas de computación como Amazon EC2, Digital Ocean, VirtualBox con REX-Ray, …. Los volúmenes proporcionan persistencia a los efímeros contenedores, por un lado almacenar datos que deban sobrevivir a la vida de un contenedor en su sistema de archivos es inadecuado ya que sus datos no son compartidos si se inicia otra instancia del contenedor y son eliminados cuando el contenedor desaparece, por otro lado en un cluster de contenedores Docker si un contenedor de un servicio finaliza inexperadamente Docker Swarm puede decidir reiniciarlo en cualquier otro nodo del cluster para mantener el estado del servicio por lo que los archivos compartidos no pueden estar tampoco en el host que hospeda los contenedores. Por estos motivos Docker Swarm necesita de un sistema de persistencia, que en este caso son los volúmenes definidos en la sección del mismo nombre volumes.
Para mayor seguridad se ha incorporado la sección secrets en la que se especifican elementos de datos como archivos que en el contenedor se montan en el directorio /run/secrets/. Algunos elementos sensibles como usuarios y contraseñas al proporcionarse como parámetros o variables de entorno aparecen haciendo un listado de procesos del sistema con sus respectivos comandos de lanzamiento y parámetros, lo que es un problema de seguridad. Hay otros elementos sensibles como claves SSH, claves privadas o certificados que ahora con los secrets no es necesario incluirlos en la propia imagen del contenedor.
La forma de iniciar y eliminar un stack en un cluster de nodos Docker Swarm es el siguiente:
|
|
|
|
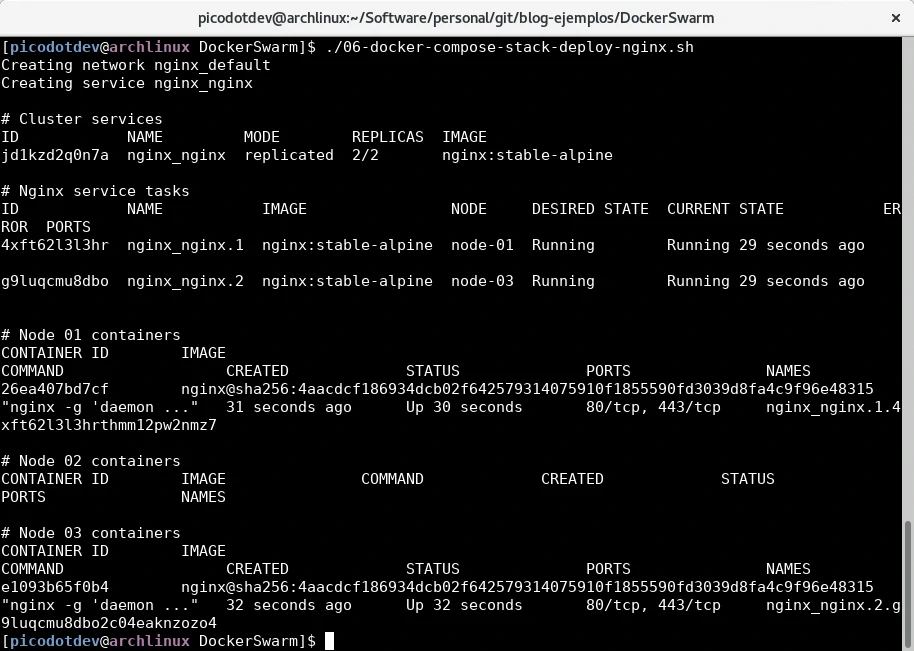
En la captura de la terminal se aprecia como estando el cluster formado por tres nodos y el servicio estando replicado con dos instancias Docker Swarm ha decidido iniciar una instancia de contenedor nginx en el nodo-01 y otra en el nodo-03 pero perfectamente podría haber iniciado una de ellas en el nodo-02. Gracias a las capacidades de networking de Docker Swarm con Routing Mesh al cualquier nodo que se le haga una petición al puerto 80 del servicio de nginx devolverá una respuesta, incluso si se hace en el ejemplo la petición al nodo-02 la respuesta será devuelta aunque en ese nodo no tenga una instancia de contenedor ejecutándose, realmente redirigirá la petición de forma transparente para el cliente la petición a un nodo que si tenga una instancia de nginx. También, al estar el servicio replicado con dos instancias Docker Swarm realizará automáticamente un balanceo de carga round-robin repartiendo las peticiones entre cada una de las instancias de nginx.
De los volumes y secrets en posteriores entregas de esta serie de artículos sobre Docker las comentaré de forma específica. El stack de servicios mostrado en este ejemplo es muy sencillo. Aunque también sencillo en el mismo código fuente del ejemplo incluyo otro stack formado por un servicio de nginx y una aplicación Java con Spring Boot que hace uso de secrets y volumes.
|
|
Un libro que me ha gustado mucho y que recomiendo leer sobre Docker Swarm es The Devops 2.1 Toolkit que lo explica detalladamente y todo el libro está orientado a como usarlo en un entorno de producción. Un libro más introductorio que también he leído y que está bastante bien es Docker in Action.
Docker Swarm es una opción simple y que está integrada en Docker pero no ofrece todas las funcionalidades de algunas otras opciones que el algunos casos de uso algo más avanzados son necesarias o convenientes. Nomad es otra opción simple para gestionar un conjunto de aplicaciones o servicios pero con algunas funcionalidades adicionales que no posee Docker Swarm como escribo en Introducción a Nomad para gestionar aplicaciones y microservicios.
El código fuente completo del ejemplo puedes descargarlo del repositorio de ejemplos de Blog Bitix alojado en GitHub.